
Web scraping with Node.js allows developers to collect and use website data quickly and efficiently. It is useful to make smarter decisions, automate tasks, and enhance digital projects. The process is easy and feasible as Node.js is speedy and is compatible with JavaScript. Mastering this skill will create new prospects of dealing with real-time information and putting it into practical use in the contemporary web development projects.
This blog describes the concept of web scraping and how web scraping works in a step-by-step manner. You will get to know what web scraping is, why you should use Node.js, and how to begin using it in your projects. All ideas are simple to comprehend and straightforward. At the end, you will have a clear background on how to effectively gather, store and utilize web data for real-life applications.
What is Node.js Web Scraping?
Web scraping with Node.js lets developers collect website data automatically and use it for real projects. Node web scraping refers to the creation of scripts that will retrieve web documents. These scripts read their contents and retrieve information such as prices, contacts, or news. It is easy to process static sites with such tools as Axios or Cheerio. The interactive websites can be managed with the aid of Puppeteer. The speed and efficiency of Node.js ensure a more scalable and faster scraping.
The Node web scraping operates by making requests, retrieving HTML, and extracting data on the page. JavaScript is used to handle both the static and dynamic sites. Using Node.js, developers have the ability to automate the process of logging in to a website. They can click buttons and gather information on numerous websites simultaneously. This strategy makes the process effective, valid, and prepared to apply it in the real world.
Curious why developers choose Node.js for large-scale web scraping? Explore the advantages of Node.js to see how its performance and event-driven model simplify data extraction.
Key Benefits of Web Scraping with Node.js
High-speed and efficient web scraping with Node.js provides developers with a quick and efficient tool to deal with web data. It assists teams to process vast information without any additional effort. These are the best advantages that make Node.js a robust option in the collection and use of data in real projects.
1. Fast and Efficient Processing
A Node.js scraper does not have to wait to make a number of web requests. Node.js web scraping will allow you to gather massive data within a short time.
2. Handles Modern Websites
It is common to use dynamic JavaScript loading content on websites today. Such tools as Puppeteer or Playwright allow developers to see a complete page and obtain data correctly.
3. Single Language Development
JavaScript can be utilized by developers to perform front-end and backend scraping. This makes coding easier and allows the workflow to be similar.
4. Wide Range of Tools
Node.js scraper may utilize such libraries as Axios to make requests, Cheerio to process them, and Puppeteer to automate. These are the tools that can make web scraping using Node.js flexible to any project.
5. Scalable for Growth
The ability to work with large number of data streams simultaneously makes Node.js relevant to the large-scale web scraping project. It is capable of expanding along with your data requirements.
6. Easy Integration
Scraped information is often included in the form of JSON, which is automatically processed by the Node.js. This information may be inputted directly into web applications, databases, or analytics pipelines.
7. Automates Repetitive Tasks
Web scraping with Node.js provides an ability to log in, click on buttons, and scroll the pages automatically. A scraper made with Node.js saves time and makes the data collection regular.
8. Real-Time Data Monitoring
Using a Node.js scraper, it is possible to make continuous updates on the sites. This assists in the collection of new information within a short time to analyze or report.
Looking to ensure your Node.js scraping applications run fast and efficiently? Check out web performance with Node.js to learn how optimization techniques improve speed, scalability, and reliability.
Steps to Build a Node.js Web Scraper
Web scraping with Node.js lets developers collect data efficiently and apply it to real projects. A scraper to build needs the right planning and procedures. The key actions to develop a Node.js web scraper and begin the data extraction process successfully include the following.
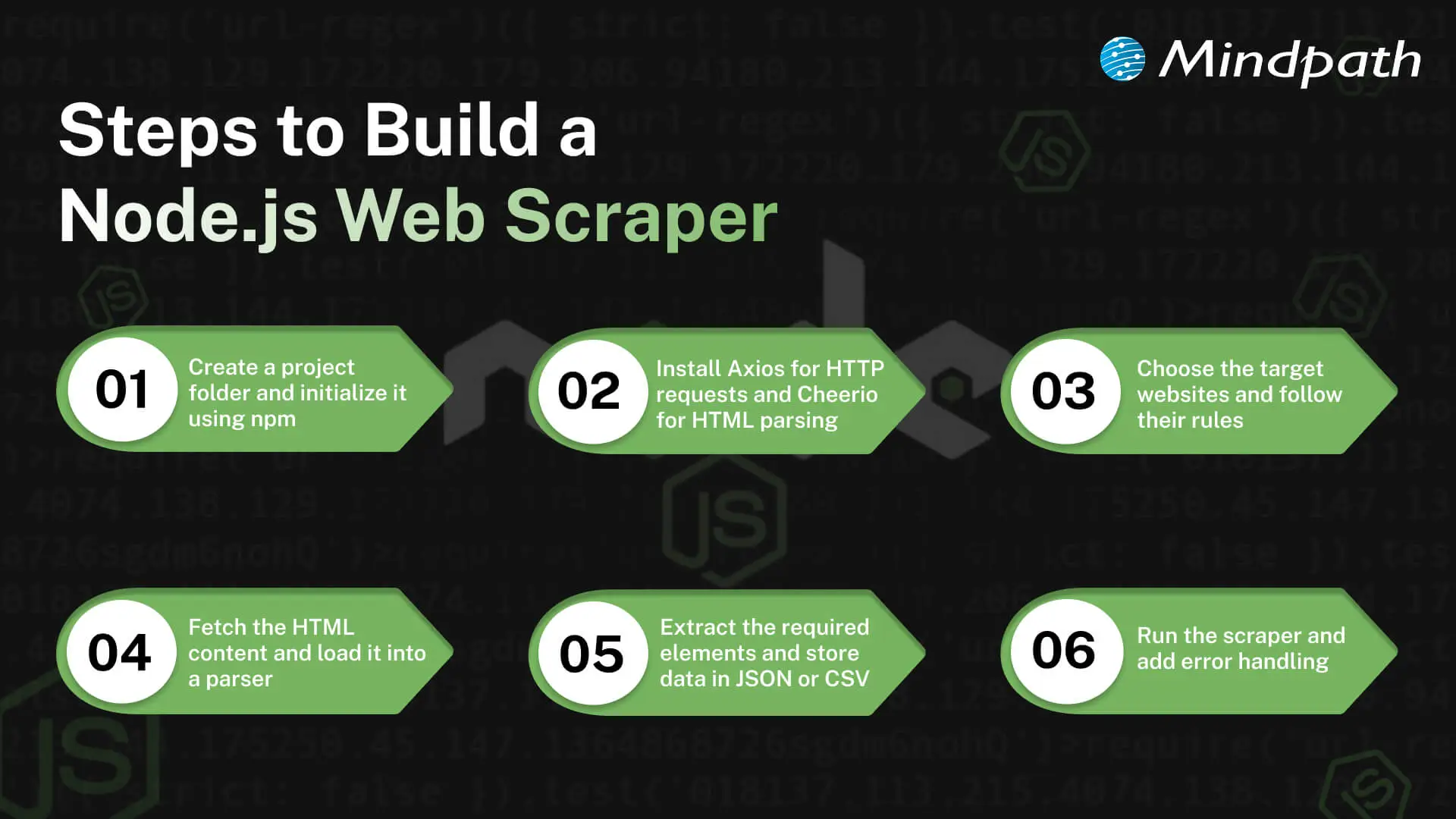
1. Set Up Your Project
Make a new project folder and get it started using npm. This prepares your Node.js environment for web scraping with Node.js. The project will manage all dependencies through a package.json file.
2. Install Necessary Libraries
Install such tools as Axios to make the HTTP requests and Cheerio as the HTML parsing tool. The libraries simplify the creation of a Node.js scraper. They give you the core tools for web scraping with Node.js.
3. Choose Target Websites
Choose the sites that you would like to scrape. Ensure that you are obeying their rules and law. Target selection helps to make sure your web scraping of Node.js is safe and effective.
4. Fetch and Parse Pages
Get the HTML of the page using Axios or any other HTTP library. Load it into Cheerio or other similar to navigate and choose elements. The next thing that needs to be done is to prepare your data that your Node.js scraper will extract.
5. Extract and Organize Data
Even define the information you require, such as prices, titles, or links. It should be collected using CSS selectors. Export the data that has been extracted in a simple, easy-to-use format: JSON, CSV, or database.
6. Execute and Improve
Install and run your Node.js scraper and verify the output. Include error management and rate limiting to prevent problems. Refining your process ensures web scraping with Node.js runs smoothly and efficiently.
Looking to simplify web scraping with Node.js? Explore essential Node.js libraries to make data extraction faster and more reliable.
Ready to Unlock the Power of Web Scraping with Node.js?
Web scraping with Node.js allows developers to collect and use data efficiently, making it easier to support smarter decisions, automation, and digital innovation. By understanding the right tools, techniques, and workflows, businesses that hire Node.js developer can work seamlessly with both static and dynamic websites, manage large datasets, integrate data into applications, and gain real-time insights to enhance project prosperity
Mindpath is a trusted Node.js development company offering expert web and Node.js development services to build fast, scalable, and secure applications. Their team creates custom solutions for web scraping, data integration, and automation. With experience in modern technologies, they deliver efficient and reliable results. Choosing Mindpath ensures your Node.js projects run smoothly, save time, and meet your business goals with high-quality support.





